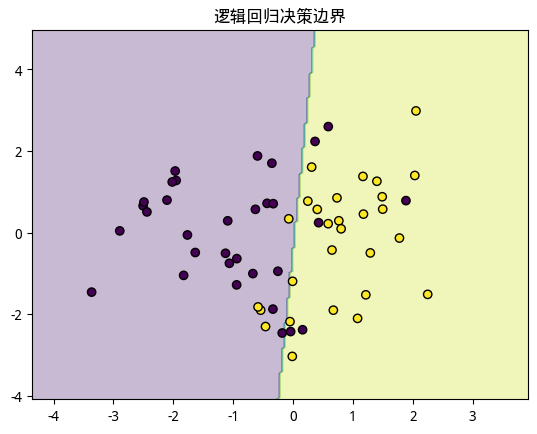
逻辑回归
概念
与线性回归预测连续值不同, 逻辑回归(Logistic Regression)是一种用于二分类问题的统计模型.它通过使用逻辑函数(Logistic Function)将线性回归的输出映射到0和1之间, 从而预测样本属于某一类别的概率.
数学原理介绍
以垃圾邮件分类为例, 假设我们有以下源数据
| 敏感词个数X1 | 是否陌生邮箱X2 | 真实标签Y(1=垃圾邮件, 0=正常邮件) |
|---|---|---|
| 5 | 1 | 1 |
| 2 | 0 | 0 |
| 3 | 1 | 1 |
| 1 | 0 | 0 |
| 4 | 1 | 1 |
对应的线性回归模型为
$$
Y = \theta_0 + \theta_1 X_1 + \theta_2 X_2
$$
其中
- $\theta_0$是偏置项
- $\theta_1$是敏感词个数的权重参数
- $\theta_2$是是否陌生邮箱的权重参数
首先把$\theta_0, \theta_1, \theta_2$初始化为0
接着带入上面每个X1, X2的值, 可以得到对应的Y值
然后我们通过Sigmoid函数, 将线性回归的输出映射到0和1之间, 计算预测概率
$$
\hat{y} = \sigma(Y) = \frac{1}{1 + e^{-Y}}
$$
这样子, 给定任意一个X1, X2, 我们都可以计算出对应的预测概率$\hat{y}$
我们期望的是
- 当真实标签Y=1时, 预测概率$\hat{y}$尽可能接近1
- 当真实标签Y=0时, 预测概率$\hat{y}$尽可能接近0
当然现在还做不到, 因为$\theta_0, \theta_1, \theta_2$都是默认初始化的0, 由此计算出的对应的预测概率$\hat{y}$也都是0.5
我们需要一个训练过程, 来得到一组最优的$\theta_0, \theta_1, \theta_2$
为此, 我们来先定义一个损失函数, 计算预测值与真实值的差距, 一般逻辑回归用交叉熵损失函数(Cross-Entropy Loss)比较多, 公式为
$$
Loss_i = -[y^{(i)} \log(\hat{y}^{(i)}) + (1 - y^{(i)}) \log(1 - \hat{y}^{(i)})]
$$
其中
- $y^{(i)}$是真实标签, 也就是0或1
- $\hat{y}^{(i)}$是预测概率, 也就是Sigmoid函数的输出
总损失为
$$
Loss = \frac{1}{n} \sum_{i=1}^{n} Loss_i
$$
接下来我们要计算总损失对$\theta_0, \theta_1, \theta_2$的梯度, 数学推导就不管了, 直接看公式
$$
\frac{\partial Loss}{\partial \theta_j} = \frac{1}{n} \sum_{i=1}^{n} (\hat{y}^{(i)} - y^{(i)}) x_j^{(i)}
$$
其中
- $j$表示$\theta$参数的索引, 也就是0, 1, 2
- $x_j^{(i)}$表示第i个样本的第j个特征, 也就是X1或X2
- $\hat{y}^{(i)}$是第i个样本的预测概率
- $y^{(i)}$是真实标签
- $n$是样本总数
以这个为例
| 偏置项X0 | 敏感词个数X1 | 真实标签Y(1=垃圾邮件, 0=正常邮件) | Sigmoid预测概率$\hat{y}$ |
|---|---|---|---|
| 1 | 0 | 0 | 0.3 |
| 1 | 3 | 1 | 0.6 |
$$
\frac{\partial Loss}{\partial \theta_0} = \frac{1}{2} [(0.3 - 0) * 1 + (0.6 - 1) * 1] = -0.05
$$
$$
\frac{\partial Loss}{\partial \theta_1} = \frac{1}{2} [(0.3 - 0) * 0 + (0.6 - 1) * 3] = -0.6
$$
梯度为负, 表明增大$\theta_0, \theta_1$可以减小损失
$\theta_1$的梯度更大, 说明增大$\theta_1$对减小损失的影响更大
接下来, 我们使用梯度下降法来更新参数
$$
\theta_j = \theta_j - \alpha \frac{\partial Loss}{\partial \theta_j}
$$
其中
- $\alpha$是学习率, 也就是每次更新的步长
- $\frac{\partial Loss}{\partial \theta_j}$是损失函数对参数的梯度
- $j$表示参数的索引, 也就是0, 1, 2
也就是说, 按照梯度, 每次把$\theta_0, \theta_1, \theta_2$都增大一点点, 这样子损失就会越来越小, 预测概率也会越来越接近真实标签
最终, 经过多次迭代, 我们会得到一组最优的$\theta_0, \theta_1, \theta_2$
这就是逻辑回归的基本原理
代码实现
下面是一个使用Python和Scikit-Learn实现逻辑回归的简单例子
1 | import numpy as np |