线性回归和最小二乘法
概念介绍
线性回归(Linear Regression) : 从一堆有相关性的数据里(比如 “每天学习时长” 和 “考试分数”、“店铺租金” 和 “月销售额”),画一条最贴合所有数据点的直线,用这条直线来描述数据的规律,还能用来预测未来。
画线性回归的这条直线的方式有很多, 最常用的一种是
线性最小二乘法(Least Squares Method) : 找到一条直线, 使得所有点到这条直线的垂直距离的平方和最小(二乘指的就是平方)
线性最小二乘法只是最小二乘法在线性回归中的应用, 最小二乘法也可以用在非线性回归中, 也就是说画的不是一条直线, 而是曲线, 不过原理都是一样的
对比起来, 另一种线性回归的方法是
最小绝对偏差法(Least Absolute Deviations, LAD) : 找到一条直线, 使得所有点到这条直线的垂直距离的绝对值和最小
相比起来, 最小二乘法有几个优势
- 最小绝对偏差法会导致正负误差相互抵消, 而最小二乘法不会
- 最小二乘法的误差函数是连续可导的, 也就是一条直线, 便于使用微积分求解, 且存在唯一的最小值, 而最小绝对偏差法的误差函数不可导, 数学可解性很差
- 最小二乘法对大误差更敏感(平方后放大), 也就是对离群点更敏感, 这在某些场景下是有优势的
最小二乘法数学解
线性回归的数学目标是
$$
S(a,b) = \sum_{i=1}^n e_i^2 = \sum_{i=1}^n [y_i - (a x_i + b)]^2 \to \text{最小}
$$
矩阵解法是
$$
\hat{\theta} = (X^TX)^{-1}X^Ty
$$
其中的$\theta$是[a, b]向量, a是斜率, b是截距
暂时理解到此, 后续会结合代码进一步理解, 不过背后的数学原理就不用理解了, 只要知道这是线性回归的数学矩阵解就行了
安装中文字体
我在WSL环境下, matplotlib会有中文显示问题, 需要安装下中文字体
1 | sudo apt install -y ttf-wqy-microhei ttf-wqy-zenhei |
1 | # 检查系统中可用的中文字体及其路径 |
1 | import matplotlib.font_manager as fm |
代码实现
先上代码
1 | import numpy as np |
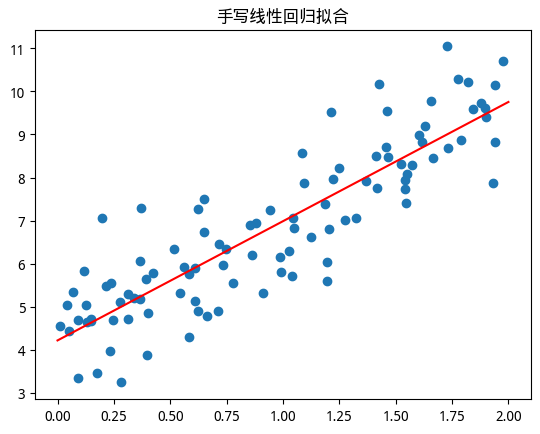
接下来逐步解释
1 | # 设置种子, 确保可复现 |
1 | X = 2 * np.random.rand(100, 1) |
np.random.rand(dim1, dim2, ...): 生成[0, 1)之间均匀分布的随机数, 形状为(dim1, dim2, …)np.random.rand(100, 1): 100行1列的二维数组, 每个数字都是[0, 1)之间的随机数X = 2 * np.random.rand(100, 1): 将这些随机数放大到[0, 2)之间
1 | y = 4 + 3 * X.flatten() + np.random.randn(100) |
X.flatten(): 将二维数组X展平为一维数组, 也就是100个[0, 2)之间的随机数y = 4 + 3 * X.flatten()这里得到的y=4 + 3x套用上面的X的值后, 对应的ynp.random.randn(100): 生成100个符合标准正态分布(均值为0, 方差为1)的随机数, 这些随机数没有上下限, 但是因为是正态分布, 所以大部分数值会集中在均值附近, 基本都在[-3, 3]之间. 作用是作为噪声值加到y上, 模拟真实场景中数据的波动y = 4 + 3 * X.flatten() + np.random.randn(100): 实际结果就是模拟了一批大致符合y=4+3x线性关系的点, 但是因为有噪声, 所以不会完全在一条直线上
1 | X_b = np.c_[np.ones((100, 1)), X] |
np.ones((100, 1)): 生成100行1列的矩阵, 每个数值都是1np.c_[A, B]: 按列拼接矩阵A和B, 这里的X_b就是个100行2列的矩阵, 第一列全是1, 第二列是X的值- 为什么要搞这么一步, 因为前面提到$\theta$就是[a, b]向量, 所以如果把X转为了$X_b$后, 那么$\theta * X_b$就等价于$aX + b1$, 也就是线性方程$y = ax + b$了. $\theta$和$X_b$都是矩阵, 方便后续矩阵运算
np.linalg.inv(M): 计算矩阵M的逆矩阵X_b.T: 矩阵X_b的转置矩阵A.dot(B): 矩阵A和B的矩阵乘theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y): 计算线性回归的数学解, 也就是前面提到的$\hat{\theta} = (X^TX)^{-1}X^Ty$print("手写解 θ0, θ1:", theta_best): [4.21509616 2.77011339], 也就是拟合出来的线性方程是$y=2.77x + 4.22$左右, 和我们生成数据时的真实线性方程$y=3x + 4$还是挺接近的
1 | X_new = np.array([[0], [2]]) |
X_new = np.array([[0], [2]]): 这里是随便找的两个x值, 0和2, 用来画线, 任意两个不同的值都行X_new_b = np.c_[np.ones((2, 1)), X_new]: 同样是添加偏置项, 变成[[1, 0], [1, 2]]y_pred = X_new_b.dot(theta_best): theta_best是刚才算出来的线性方程的系数, 这里就是计算出x=0和x=2时对应的y值plt.scatter(X, y): 画出之前生成的100个点plt.plot(X_new, y_pred, "r-"): 画出拟合出来的线性方程, “r-“表示红色实线



