随机森林算法
概述
随机森林(Random Forest)很容易理解, 就是Bagging集成学习算法, 分类器全采用CART决策树
简单来说就是, 随机选几行几列, 训练一个决策树, 再次随机选几行几列, 再训练一个决策树, 继续以此类推搞他100个决策树, 然后输入数据给每个决策树, 票多者胜
与CART的不同
分类时不是每个类对算出GINI值, 而是随机圈出m个类(m一般为类数的开方), 仅对该m个类进行GINI值计算, 并分类
举例, Boostrap采样后数据集如下
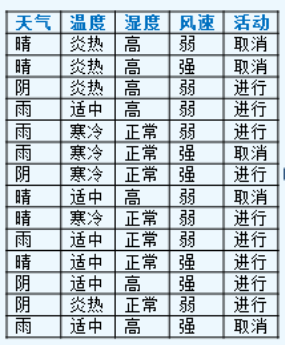
注意采样还是整行都采, 每一列都采
然后随机决定几列(天气/湿度), 只计算这俩的GINI值, 发现天气GINI值更低, 就以天气进行分类
这样的目的是为了保证行随机采样(Boostrap采样实现)和列随机采样(随机圈出m个类实现)
两种随机保证了不容易出现过拟合, 因此随机森林不同于CART决策树, 不用剪枝
sklearn demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
print (df)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
test_pred=clf.predict(test[features])
preds = iris.target_names[test_pred]
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])
|
代码出处-随机森林实战教程-Python-Demo
参考资料
机器学习九大算法—随机森林
随机森林原理介绍与适用情况(综述篇)
随机森林实战教程-Python-Demo
决策树与随机森林
[Machine Learning & Algorithm] 随机森林(Random Forest)



