集成学习
概述
一个分类器(决策树/神经网络等), 能力有限, 不一定对, 那么拿很多分类器, 结果投票得到, 那么准确率会高很多, 这就是集成学习
集成学习两大算法: Bagging 算法和Boosting 算法
Bagging算法/装袋算法
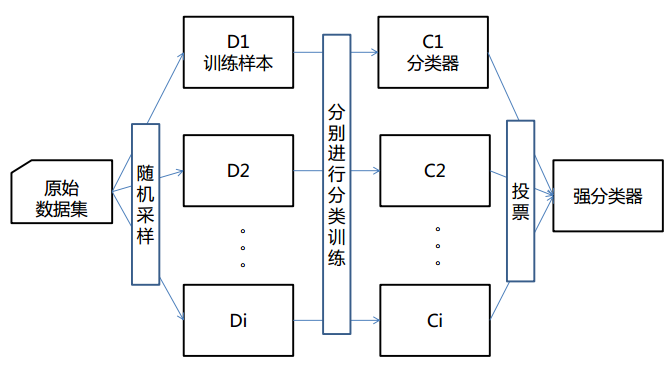
模式如上图
原始数据集(假设有100条数据), 通过Bootstrap采样方法进行采样
Bootstrap采样: 有放回的采样, 采样数目等同于原始数据集, 即采样100个, 即D1=D2=…=Di=100, 但是因为是有放回采样, 所以会有重复, 所以D1/D2/…./Di基本不相同
D1/D2/…./Di每个样本各自选择一个分类器进行训练, 分类器只和对应训练样本在一起训练, 和其他训练样本不交流, 然后得到训练好的i个分类器: C1/C2/…./Ci
然后进来一个数据要预测, 就通过各个分类器, 得到i个分类结果, 最多的则为最终分类结果
可见Bagging算法除了Bootstrap采样略微复杂点, 其他都很普通容易理解
Boosting算法
原始数据集(假设有100条数据), 每条数据分配一个相同的权重(1/100), 然后训练一个分类器1, 完成后, 因为分类器不是100%能对这训练集100条数据进行分类(能就过拟合了), 所以将那些分类器1分类错误的数据权重提高, 分类正确的数据权重降低.
再次训练一个分类器2, 训练过程更加关注权重大的数据, 也就是分类器1分类错误的数据, 完成后将分类器2分类错误的数据权重提高, 分类正确的数据权重降低.
以此类推得到i个分类器, 100条数据也分别有不同的权重, 然后100条数据的权重就没用了, 这100条数据的权重只是为了生成i个分类器.
过程中, 每个分类器生成后也会赋予一个不变的权重, i个分类器依次生成完毕后, 就得到i个分类器权重, 相加起来有公式保证为1, 这i个分类器权重就是投票权重.
接下来, 就是流入数据, i个分类器给出分类结果, 按照各个分类器的权重, 得出最终分类结果
其他
Bagging/Boosting是传统集成学习算法
现在有更好的, AdaBoost/GBDT



